Camunda: Overview
Some time ago, I changed the company where I worked. And of course, a new company has its unique set of technologies I never worked with.
One is a software system that automates business processes - Camunda.
Brief explanation
From a high-level perspective, this software provides a cool ability to convert BPMN diagrams into real actions. Camunda has a tool that allows the creation of BPMN diagrams and exports them into XMLs that can be fed to Camunda's engine.
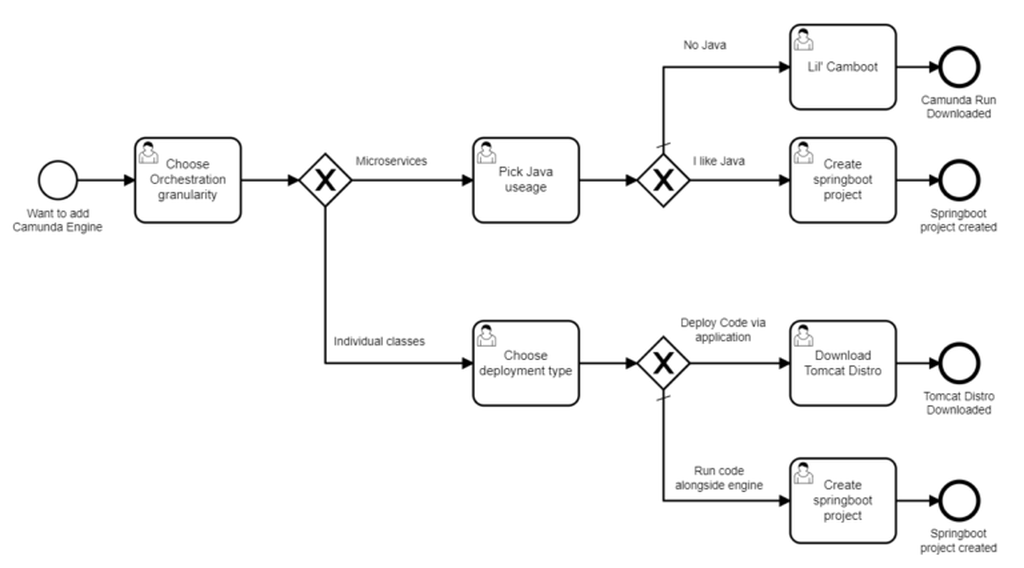
The image above is just an example taken from the internet. However, It really shows what BPMN diagrams look like. Each square represents an action (job) that Camunda will execute. Under the hood, you can write your own Java code that will be executed during the job. Basically, this is the main feature of Camunda and its business value - to introduce a connection between developers and process analysts. I already started talking about the code, so it makes sense to discuss the architecture of Camunda.
Architecture
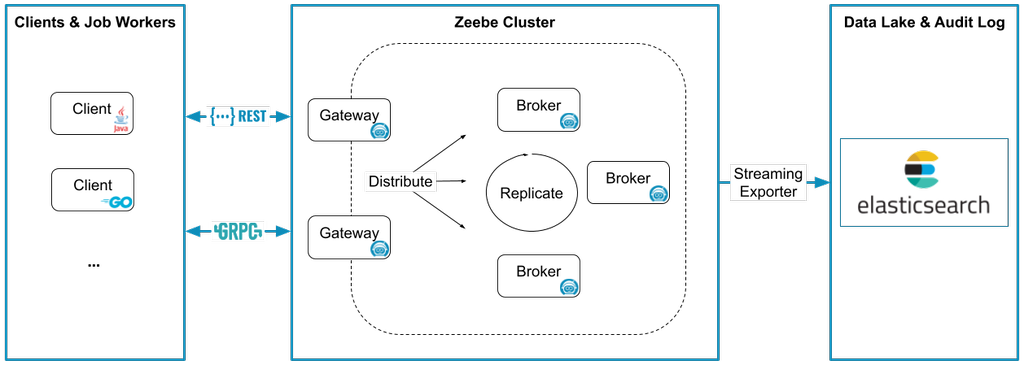 I took this diagram from the official Camunda website and it looks terrible in the dark mode. Sry🙈 I'll fix it someday...maybe...
I took this diagram from the official Camunda website and it looks terrible in the dark mode. Sry🙈 I'll fix it someday...maybe...
There are two major versions in production (7 and 8), and they are different from the architecture point of view, so let's discuss only the latest one. The architecture is presented in the image above.
The key components here are:
- Zeebe cluster
- Data lake
- Clients
- Job workers
The core of the system is the Zeebe cluster. It is a workflow engine, so it stores the current process state, intermediate values, job timeouts, transitions between jobs, etc. Based on the official documentation it has great scalability options, so can handle dozens of processes, jobs, and states. I didn't test that and our system is not so big, we don't have trillions of processes/jobs, so I just leave this statement about performance as is.
The next element of the system is the Data lake. Usually, it is presented as Elasticsearch, but you may use anything you want because of the ability to write your own data exporter. This exporter will be notified by Camunda about new events. You may store, process, ignore, or do whatever you want with this data. Quite simple.
Clients can be any application/service that utilizes the Camunda API (REST, GRPC) to manage processes (start, stop, message) and get info about their states.
The more interesting part of the system is Job workers. In general, the job workers are services that will be called by Camunda to perform the jobs described in the BPMN diagram. In a perfect world these workers are stateless, so Camunda handles all input and output data and the job worker just needs to perform some manipulations with that data.
Summary
Camunda is an interesting tool, it has its own purpose and customers that are interested in it. Different businesses will definitely find benefits from integrating it. From a technical perspective, Camunda is quite customizable, so some parts of the system can be disabled if you don't need them. So far, I'm working with Camunda not too much time to have a full picture, but some items I can highlight already.
Above all, Camunda isn't free. You need to buy the license first and also pay a yearly fee to use it.
Let's start with something obvious. Camunda is written in Java and if you or your company wants to integrate it, you'll certainly need to have Java expertise.
Another important point is that if your company plans to use Camunda you need to be ready to code additional modules like exporters, connectors, and job workers. Camunda certainly provides you all examples that show how easily complex processes can be created but these examples are 100% synthetic and will not match your requirements.
This item is a result of the previous one. The final architecture will be more complex than you expect. Camunda has mechanisms to transfer data between jobs but it creates additional load for Elasticsearch because Camunda stores this data there. As a result, you'll have additional data storage that will be used by a job worker.